It’s easy to get in the habit of developing “one off” source-specific ELT flows, but over time these become too large to manage effectively. In this blog, we’ll illustrate a powerful pattern that allows you to reuse components and code so that development for each new source table is fast and the entire pipeline is scalable. The end user experience is frictionless as a result of the target tables being “always on.” All of this means less interruptions for both analysts and developers so everyone can focus on actionable insights!
This is the first part of a two-part blog series. In Part Two, we revisit this pattern to make a few improvements to further reduce the development effort when adding new tables.
Using Matillion and an ELT Approach
The first step in any data syncing job is to extract the data from the source, load it into the data warehouse, and then perform transformations. The underlying patterns here can be used in any implementation and technology.
In this case we are using Matillion, one of our favorite data pipeline tools. Matillion uses a modern extract, load, and transform (ELT) approach instead of the more traditional ETL approach because Matillion is architected to directly integrate with a cloud data warehouse to utilize the horsepower of the data warehouse’s query engine for heavy lifting.
Building Scalable Systems
Design patterns like the one we discuss in this blog allow data engineers to build scalable systems that reuse 90% of the code for every table ingested. Although it requires more work up front, once pattern development is complete all that is required to start ingesting a new table/object is to insert a row into a custom metadata table and perform a simple one-time setup of your desired target table.
Depending on the structure and responsibilities of your team, you can even hand off adding tables for ingestion to a less technical resource once you are confident in the job’s performance.
“Always On” Target Tables
Another benefit of this pattern is what we are calling “always on” target tables. This means that end-users and applications that query the data warehouse target tables will never experience a delay, even if a job is simultaneously updating those tables. This has been a long-standing challenge in ELT design and one that inexperienced data engineers often neglect.
For example, suppose a source table simply needs to be replicated in your warehouse. Seems like an easy task—just truncate the target table in the warehouse and reload with the new data from the source. The problem here is that 1) reload can take a long time (sometimes hours) every time your ELT job runs, and 2) data will be incomplete in the target table while it reloads.
This may not be an issue for a 24-hour load scheduled at 12AM, but once you get into more frequent intervals (twice daily, 4x daily, hourly), your end users will surely be impacted and it won’t be long before the engineering team is getting calls about long query times—or even worse, missing data.
The pattern below leverages a technique which ensures your replicated target tables are “always on” so your end users are never waiting for ELT processes to complete, and data is never incomplete.
General Structure
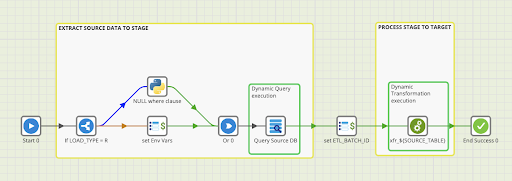
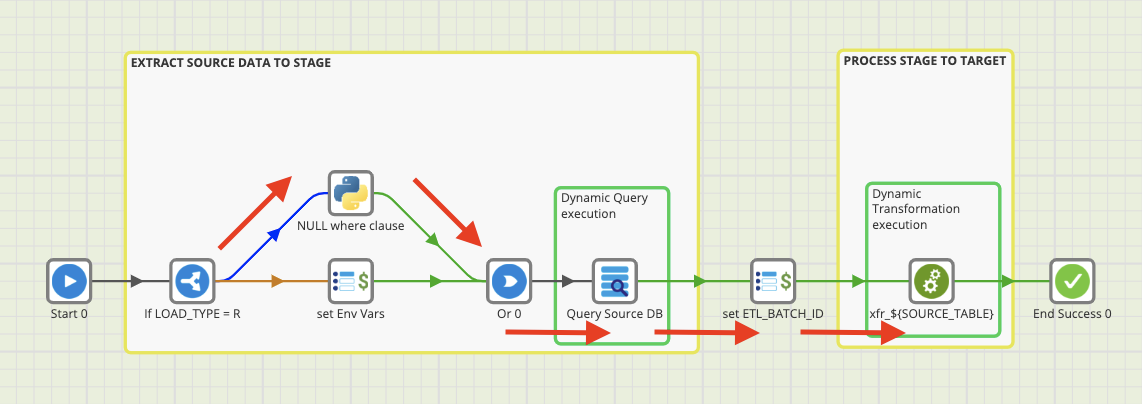
The image above depicts a Matillion orchestration created to handle replication of a source database’s tables into a Snowflake data warehouse. (NOTE: Matillion integrates with all major cloud data warehouses).
There are two types of loading accounted for here, which we will get into more detail on later. The general pattern is:
- Extract data from the source system
- Load that extract into a temporary staging table
- Move the staged data to a permanent target “replicated” table
“Drag and drop” ELT tools like Matillion make source-to-warehouse replication a simple task for one source table. And over time, one’s proficiency with a tool could make adding a new table a minor inconvenience. However, after 10 or 20 tables you are looking at a bloated ELT environment with too many artifacts to manage effectively if changes are needed. But there is a better way!
The power of this pattern lies in the ability to use variables which are populated by a custom metadata table that we have created (in Snowflake, in this example). A simple example is depicted below:
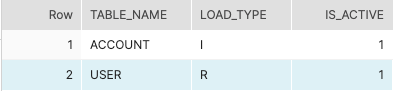
TABLE_NAME: corresponds to the name of the source table
LOAD_TYPE: is an indicator of ELT load method (I = Incremental, R = Reload)
IS_ACTIVE: is a handy boolean field which can be used to turn on/off loading for a specific table
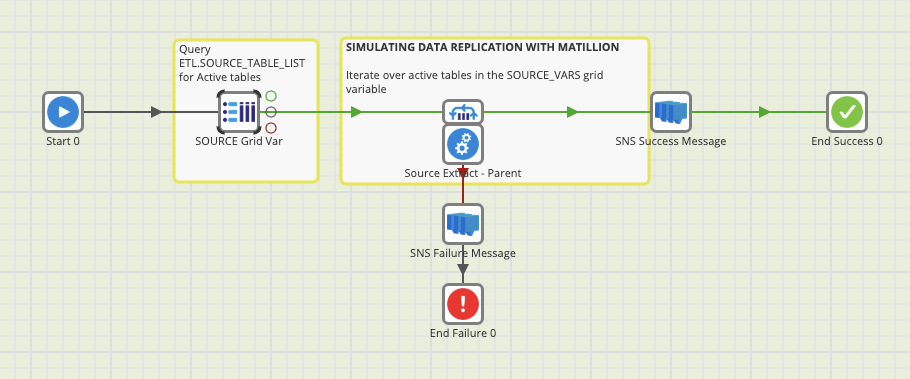
The final piece of the puzzle is an iterator provided by Matillion. In this case we are using a grid iterator to loop over the metadata table’s rows which are stored in a two-dimensional array much like a table (aka, a grid). The metadata table is interrogated at the beginning of every run to get the TABLE_NAME and LOAD_TYPE of all records where IS_ACTIVE = 1. The result of that is stored in the grid.
The orchestration above has been created to manage the metadata table iteration so that the Source DB extract orchestration is run for every TABLE_NAME, LOAD_TYPE pair.
Now that we have a high-level understanding of the orchestration flow let’s take a closer look at the processing for our two table types.
Scenario 1: Incremental Upsert (Account)
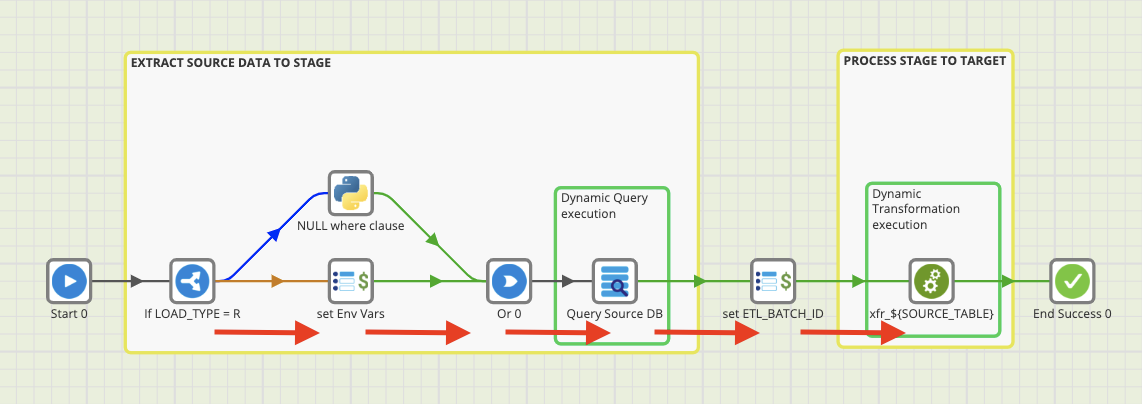
For our first table “Account” we are incrementally extracting data using LastModifiedDate as our key to determine which records are eligible for extraction.
Step 1:
The first step is to check what table type we are processing using an “If” component. In this case the account table is an incremental load (LOAD_TYPE = I). So we will bypass a conditional step we take for reload tables.
Step 2:
Next we query our target table to get the MAX(LastModifiedDate) and update the ${MAXLASTMODDATE} variable which is used in the next step.
Step 3:
Using Matillion’s generic Database Query component, we are able to query our source database for our desired data (shown below) and load the result to an intermediary “staging” table. Here we see the variables which are updated at runtime allowing us to reuse this component for any table within this database:
![]()
- ${SOURCE_TBL}: evaluates to the name of the table which is being processed (Account)
- ${WHERE_CLAUSE}: is defined as “where LastModifiedDate > ‘${MAXLASTMODDATE}’”. The value from the previous step is inserted into the clause and we will only query for records with a LastModifiedDate greater than ${MAXLASTMODDATE}.
Step 4:
We run another query to get the current epoch timestamp which is appended to our staging data and serves as an id which can be used to group the current run’s data together (${ETL_BATCH_ID}).
Step 5:
The final step is to move the data from staging to the target replicated table. We are able to run a transformation within the orchestration above and we are dynamically selecting the transformation based on the ${SOURCE_TABLE} variable.
The transformations we would like to run in this orchestration have been strategically named (see below) so that at runtime the transformation for the corresponding table is referenced for the stage to target move. In this case we will run the xfr_ACCOUNT transformation.

In xfr_ACCOUNT the data in staging is selected, the ${ETL_BATCH_ID} from step 4 is added to every row, and the result of that is upserted into our target table. For those unfamiliar, an upsert is the process of updating data for records that already exist in a table (identified by a defined key) or inserting data for records that do not already exist in a table. This is how we are able to ensure the table is “always on.” At no point is the table dropped ensuring uninterrupted access for your end user.
Scenario 2: Full Table Upsert (User)
Our source table may not have a reliable incremental key for us to extract data. In these cases we can pull all of the table’s data and use this in a Full table Upsert to keep our table in sync. You will notice we are using the same diagram for the “User” table but the flow is slightly different as we are extracting data to reload the entire table.
Step 1:
We check the table type and this time the “If” component evaluates to true (LOAD_TYPE = R).
Step 2:
This takes us to a python component where we are leveraging built-in functions to update the ${WHERE_CLAUSE} variable to an empty string because we are not filtering on an incremental key.
Step 3:
Using the exact same component as the previous table we are now pulling all “User” records from our source database because no where clause is applied to the Database Query component.
![]()
- ${SOURCE_TABLE}: will be name of the table which is being processed (User)
- ${WHERE_CLAUSE}: is an empty string as a result of the previous step
Step 4:
We query for the epoch timestamp to be appended to our data (${ETL_BATCH_ID}).
Step 5:
This time our dynamic transformation execution will result in the xfr_USER transformation being run. The exact same steps are taken in xfr_USER as the xfr_ACCOUNT. The difference here is that all User records were extracted in our query to our source database resulting in a full table upsert.
Of course, there are even more scenarios that can be built off this pattern. For instance, if the source rows can be deleted, we could extend the second scenario to compare source-to-target and to identify deleted rows and remove them from the target tables.
Real-World Example
Our data team has implemented this reusable architecture at numerous clients who want to sync source system tables / objects in their cloud data warehouse. Check out the video recording of our webinar, Pitch Fastball Analytics Like Major League Baseball, where we illustrate our implementation of this pattern to successfully expedite analytics for the San Francisco Giants and Boston Red Sox.
Building Scalable Systems
In cultivating a data-driven culture it is important to have systems that can grow as the number of source tables/objects grow. Check out Part Two of this blog: Furthering Automation in Matillion.