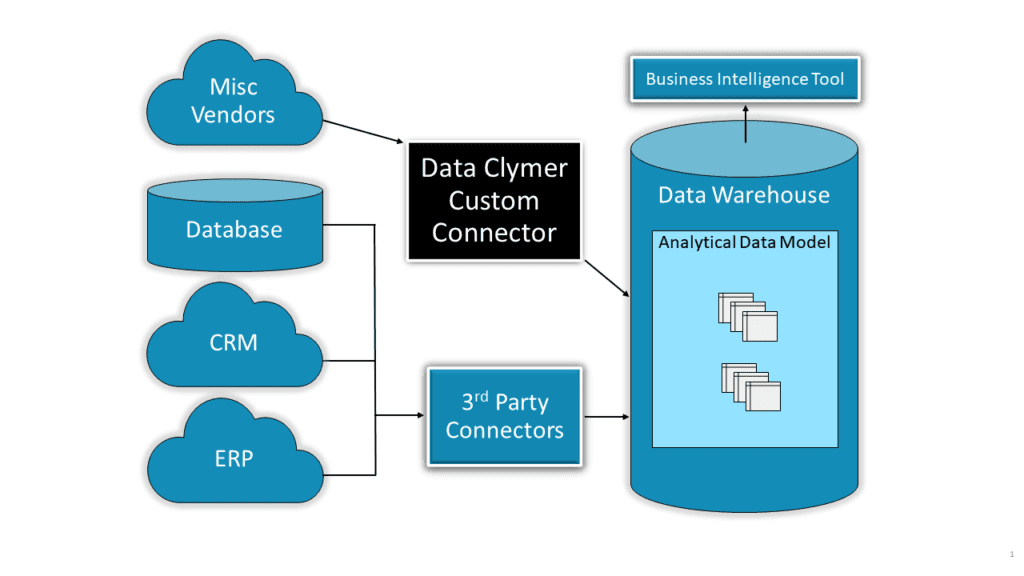
Have you ever needed to get data into your data warehouse only to discover that no one makes a connector for your data source? We encounter this all the time, and we can build that bridge for you.
Centralizing all of your data into a cloud data warehouse is the best way to enable rapid analytics, but the sheer number of data source systems can be daunting: CRM, ERP, Web and Mobile App Event Streams, Payments, Bookings, Product Usage, Spreadsheets, and countless others. Cloud tools such as Matillion, Panoply, Stitch, and FiveTran provide out-of-the-box connectors to quickly enable the flow of business data between various popular sources and your data warehouse. However, some common sources, such as PayPal, are not represented on any of these platforms. If your business relies on one or more of these unrepresented sources you will need to take a more enterprising approach to collecting and exposing data in your data stack. That’s where Data Clymer can help! We have developed a framework for building custom data connectors that utilize APIs, webhooks, and more to create optimized tables for downstream analysis.
Below are a few examples of the types of custom connectors we’ve built:
- Payments from Paypal
- Google map searches via the Google My Business API
- Store foot traffic extracted from SMS every 15 minutes for near real-time entry and exit data at multiple retail locations
We work with our clients to identify the relationship between the desired data and endpoint(s) of interest from each data source. Depending on the nature of the data returned from the API we will use one of several transformation approaches such as JSON flattening or explicit key-to-column mapping to ensure the output is amenable for use in a relational database. Oftentimes a single endpoint can yield data that maps to two or more tables.
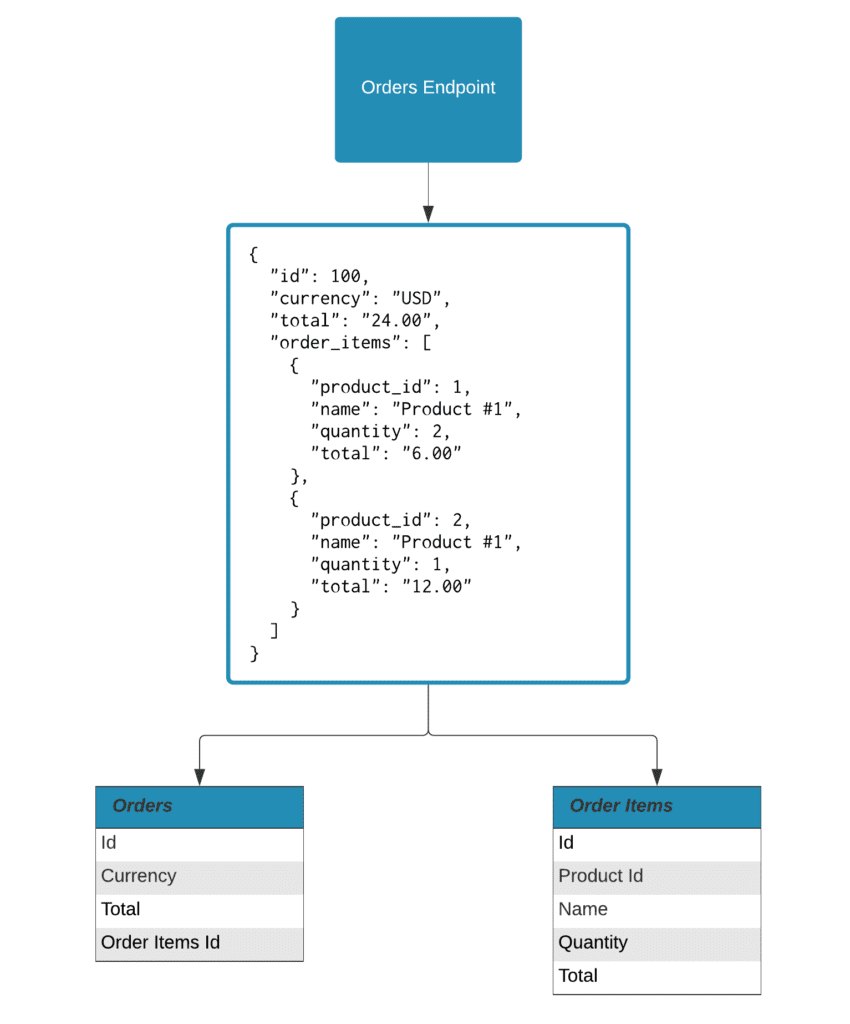
After determining the data structure, we build a fully automated process to perform an initial load of historical data as well as period incremental loads to add new data or updated changed data. Additional factors we consider are limitations imposed on API calls by the platform (i.e API rate and volume limits) and rotation of authentication keys. We have experience working within constraints of various data sources and are capable of customizing our framework as necessary.
Once the data is transformed into normalized table(s), we leverage popular object-based storage platforms such as Amazon S3 or Google Cloud Storage as a means of moving data into your data warehouse. The ubiquity of object-based storage platforms ensures that your integration tool of choice can be used to bring data into your data warehouse. Use of these cloud-based services also ensures high availability and, if desired, audit control by leveraging features such as versioning. After data is available in the data warehouse it can be analyzed alongside data from any other source, enhancing your potential to glean actionable insights from various tools within your business.
Data Clymer’s custom connector framework can easily be tailored to fit each client’s individual needs. See a list of our pre-built connectors here. We have experience implementing our framework as a managed platform on our servers or on resources hosted and managed by the client. Lastly, the custom connector framework offers desired features such as event logging and email alerts that allow you to easily monitor the data ingestion process for interruptions or unexpected behavior.